PyTorch 2026-05-19
损失函数Loss以巨量的系数为自变量
损失函数Loss以巨量的系数为自变量
梯度下降算法: 梯度就是多元函数对所有自变量偏导数排成的向量
多元函数的函数值依赖于多个变量,而梯度是对多个变量的偏导组成的向量,梯度里的每一个值都是一个偏导,而梯度所指的方向就是能让每个变量各得其所,发挥当前变化率作用的方向,就可以让每个变量都按比例配合,从而使函数值变化最快,而Δx默认是>0的,所以是函数值增长最快的方向
- 方向:梯度方向是函数值增长最快的方向;负梯度才是下降最快
- 大小:梯度向量的模长表示变化到底有多快
重点解决鞍点问题:
在某些方向看是最小点,而在另外某些方向看是最大点;而梯度下降的“视野”只有局部,看不到那些还能下降的方向,所以被“假最优”骗了过去。
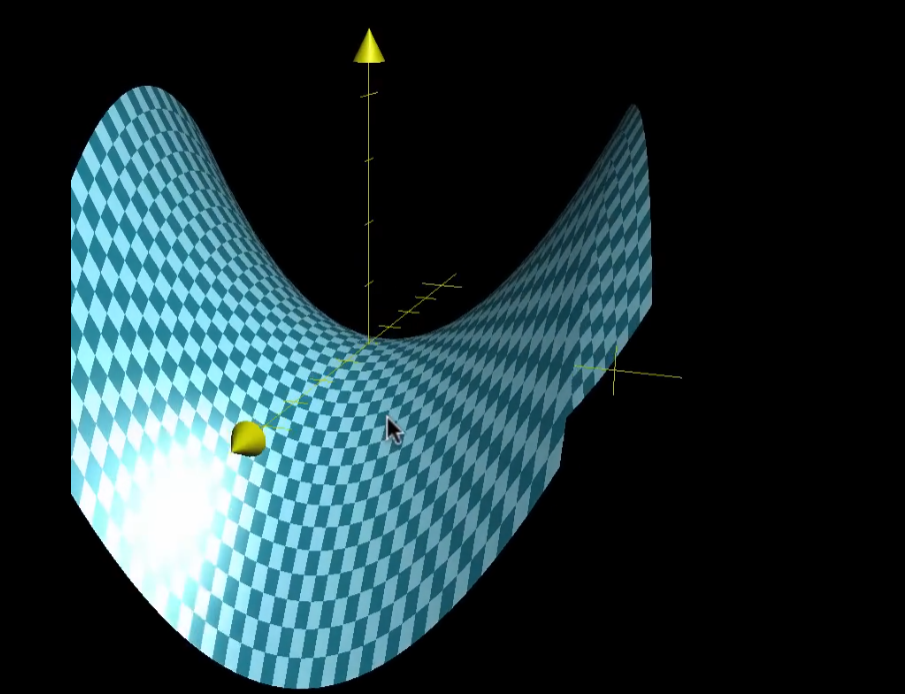
训练出现问题的原因:
- 梯度下降的目标是 让损失值最小,但它只能检测并借用 梯度为零 这个中间信号
- 梯度下降是”坐标轴近视眼” 它每一步只读梯度向量 ,也就是 n 个坐标轴方向的偏导,它天生看不见斜方向(混合方向);而鞍点恰好满足”所有坐标轴方向的偏导都是 0,但不是所有方向(坐标轴方向+混合方向)的方向导数都为0”的特性,会直击到梯度下降算法的痛点
- 根本痛点:梯度下降无法区分:
- 最低点(损失值小,该停)
- 局部极小值 (损失值不够小,该冲)(但是这样的点经实际验证很少)
- 鞍点(损失值大,该冲)(重点解决!) 它看到梯度为 0 就停,不管损失值到底小不小,这是训练崩溃的根源
梯度下降延申:随机梯度下降
 梯度下降可以并行,节约时间;性能低,随机梯度下降时间开销大,性能好;可以取折中方案:batch.每次取一组进行
梯度下降可以并行,节约时间;性能低,随机梯度下降时间开销大,性能好;可以取折中方案:batch.每次取一组进行